莫烦强化学习笔记
本文是对莫烦的强化学习课程的总结以及自己的理解,若有侵权,请联系删除
强化学习方法汇总
| 不理解环境(model-free RL) | 理解环境(model based RL) |
|---|---|
| 只根据环境反馈进行学习 | 构建出环境的虚拟模型 |
| Q Learning | model-free能用的算法model based都能用, 只不过model based可以在虚拟世界里学习 |
| Sarsa | 根据想象预判接下来要发生的事情,然后选择最好的执行 |
| Policy Gradient |
| 基于概率(policy-free RL) | 基于价值(value based RL) |
|---|---|
| 生成所有动作的概率,根据概率选动作 | 生成所有动作的价值,根据最高价值选动作 |
| policy gradients | Q Learning |
| Sarsa | |
| 基于概率和基于价值结合构成Actor-Critic, | Actor基于概率做出动作,Critic给出做出动作的价值。加速了学习过程 |
| 回合更新(Monte-Carlo update) | 单步更新(Temporal-difference update) |
|---|---|
| 基础版Policy Gradient | Q Learning |
| Monte-Carlo Learning | Sarsa |
| 升级版 Policy Gradient |
| 在线学习(on-policy) | 离线学习(off-policy) |
|---|---|
| 本人自己玩,自己学习 | 可以看着别人玩,自己学习 |
| Sarsa | Q learning |
| Sarsa($\lambda$) | Deep Q Network |
课程要求
- 学习资料
- OpenAI gym 官网
- Numpy, pandas,Matplotlib, Tkinter, Tensorflow, OpenAI gym.
Q learning
什么是Q learning
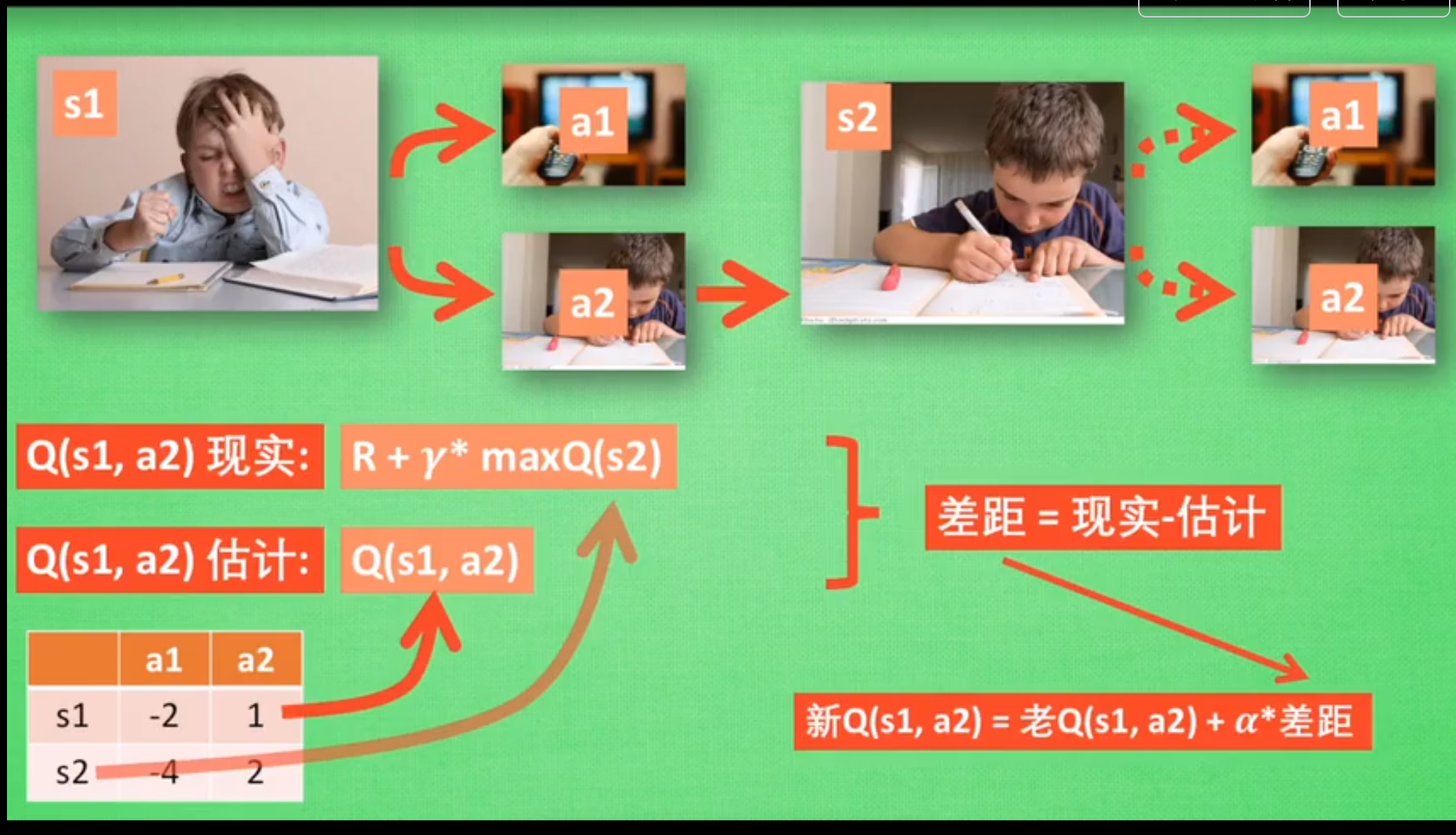
状态s1 :写作业
动作a1:看电视,a2: 写作业
Q-Learning 算法

其中
- $\varepsilon$-greedy 是一种决策方式,有$\varepsilon$的概率选择最优Q值得动作,但也有$1-\varepsilon$的概率随机选择动作。目的是能够探索新的动作。
- $Q(s,a)\leftarrow Q(s,a)+\alpha[r+\gamma\max_{a’}Q(s’,a’)-Q(s,a)]$是Q值得更新公式
- $\alpha$是学习率,$ r$是状态$s$进行动作$a$变到状态$s‘$的奖励,$\gamma$是记忆系数.
- $r+\gamma\max_{a’}Q(s’,a’)$是当前的奖励与未来的奖励的和,也就是$Q(s,a)$的现实值
- 因为$r+\gamma\max_{a’}Q(s’,a’)=r+\gamma[r’+\gamma \max_{a’‘}Q(s’‘,a’’)]=r+\gamma r’+\gamma^2 r’’+\cdots$, 也就是未来所有奖励的和, $\gamma$就是未来的奖励所占的比重系数,若$\gamma=1$,未来的奖励也同样重要, 若$\gamma=0$,就只看当前奖励,忽略未来的所有奖励。
- $Q(s,a)$是当前的估计值,用现实值-估计值,就是可以得到更新值$r+\gamma\max_{a’}Q(s’,a’)-Q(s,a)$
- 学习率$0<\alpha\le1$则决定了更新多少更新值,可以把更新值全部用上($\alpha=1$),也可以只用一部分$\alpha<1$
实战示例1 一维的贪吃蛇
import numpy as np
import pandas as pd
import time
np.random.seed(2)
N_STATES=6 #游戏的总长度
ACTIONS=['left','right'] #两个动作
EPSILON=0.9 #决策概率
ALPHA=0.10 # 学习概率
GAMMA=0.9 # 记忆系数
MAX_EPISODES =13 #最大的训练次数
FRESH_TIME =0.3 #0.3秒走一步
def build_q_table(n_satates,actions): #初始化Q值表
table=pd.DataFrame(
np.zeros((n_satates,len(actions))),
columns=actions,
)
return table
def choose_action(state,q_table): #在state状态下根据Q值表选择下一个action
state_actions=q_table.iloc[state,:]
if (np.random.uniform()>EPSILON) or (state_actions.all()==0): #有1-EPSILON的概率随机选择
action_name=np.random.choice(ACTIONS)
else: #EPSILON的概率选择最大的
action_name=state_actions.idxmax()
return action_name
def get_env_feedback(S,A): #根据当前状态S和状态A,更新下一个状态和奖励
if A == 'right':
if S == N_STATES - 2:
S_ = 'terminal'
R = 1
else:
S_ = S + 1
R = 0
else:
R = 0
if S == 0:
S_ = S
else:
S_ = S - 1
return S_, R
def update_env(S, episode, step_counter): #更新在屏幕上的显示
# This is how environment be updated
env_list = ['-']*(N_STATES-1) + ['T'] # '---------T' our environment
if S == 'terminal':
interaction = 'Episode %s: total_steps = %s' % (episode+1, step_counter)
print('\r{}'.format(interaction), end='')
time.sleep(2)
print('\r ', end='')
else:
env_list[S] = 'o'
interaction = ''.join(env_list)
print('\r{}'.format(interaction), end='')
time.sleep(FRESH_TIME)
def rl(): #强化学习的主进程
# main part of RL loop
q_table = build_q_table(N_STATES, ACTIONS) #创建初始化Q表
for episode in range(MAX_EPISODES): #遍历训练轮次
step_counter = 0 #走了多少步
S = 0 #初始化点在哪
is_terminated = False
update_env(S, episode, step_counter) #在频幕上显示
while not is_terminated: #如果不停止就一直运行
A = choose_action(S, q_table) #选择action
S_, R = get_env_feedback(S, A) # 获取下个状态和奖励
q_predict = q_table.loc[S, A] #Q的估计值
if S_ != 'terminal': #如果没有停止,就计算目标值(现实值)
q_target = R + GAMMA * q_table.iloc[S_, :].max()
else: #如果停止了就只记忆当前的奖励吧
q_target = R # next state is terminal
is_terminated = True # terminate this episode
q_table.loc[S, A] += ALPHA * (q_target - q_predict) # 更新Q值表
S = S_ # move to next state #进入下一个状态
update_env(S, episode, step_counter+1)
step_counter += 1
return q_table
if __name__ == "__main__":
q_table = rl()
print('\r\nQ-table:\n')
print(q_table)
实战示例2 走迷宫
架构与上面一样,只是状态和动作值更多了,复制粘贴上来也没意思了。源码在这里:https://github.com/MorvanZhou/Reinforcement-learning-with-tensorflow/tree/master/contents/2_Q_Learning_maze。还是很有意思的。
Sarsa
与Q Learning很相似,不同的地方在于更新方式。
Q Learning是选择下一步的最大Q值即可,下一步走哪是另一说了,说到不一定做到, Sarsa是说到做到,直接取下一步该走的Q值,所以是on-policy的

Sarsa($\lambda$)
上面的Sarsa可以称之为Sarsa(0),每走一步立即更新, 是单步更新。$\lambda$是脚步衰减值,$\lambda=1$是回合更新。

-
其中最主要的部分是加上了对访问过的路径的记忆,$\lambda$就是对以前的路径的重要性进行了刻画。然后更新的时候也会更新以前路径的Q值
-
$E(s,a)\leftarrow E(s,a)+1$可能会导致$E(s,a)$的值非常大,可能会影响收敛,可以修改为
\(E(s,a)=1,E(s,A/a)=0\), 其中$A/a$代表所有动作$A$去除了当前动作外的其他所有动作
对本文有任何问题,请在下面评论: